Les réseaux sociaux donnent l’illusion que nous participons à la vie publique pendant qu’elle se déroule ailleurs, là où nous ne la cherchons plus.
C’est une drogue dure et nocive, sans doute plus qu’on ne peut l’imaginer puisqu’on ne sait pas encore ce que deviendront demain les utilisateurs d’aujourd’hui.
I added a feature to a Lua script I wrote for Renoise ~13 years ago: Indicator lights. I got a new AKAI MPK mini so I am playing around with it again. Download Grid Pie here.
Tous les frères ont un esprit identique.
Sa force réside dans son ensemble.
La doctrine du sacrifice personnel.
Aimer son peuple d’un amour véritable,
l’aimer objectivement sans intérêt personnel,
sans aveuglement, est une voie raisonnée et pratique.
Nous travaillons pour la cause,
pas pour les éloges.
Nous cherchons une action efficace.
La fraternité chez nous est une force unifiante et non assimilatrice.
Elle ne tue pas la personnalité mais seulement l’individualisme.
Cherche le bien général.
The blog used to run on sux0r, software I wrote and hosted myself, but it was getting too old and becoming difficult to maintain. Archived it. Now she’s on WordPress.
I’m sharing this animation my 12 year old made for her big elementary school graduation ceremony. I am very proud of her. (In Québec, highschool starts in grade 7. Bonne chance pour la prochaine étape!)
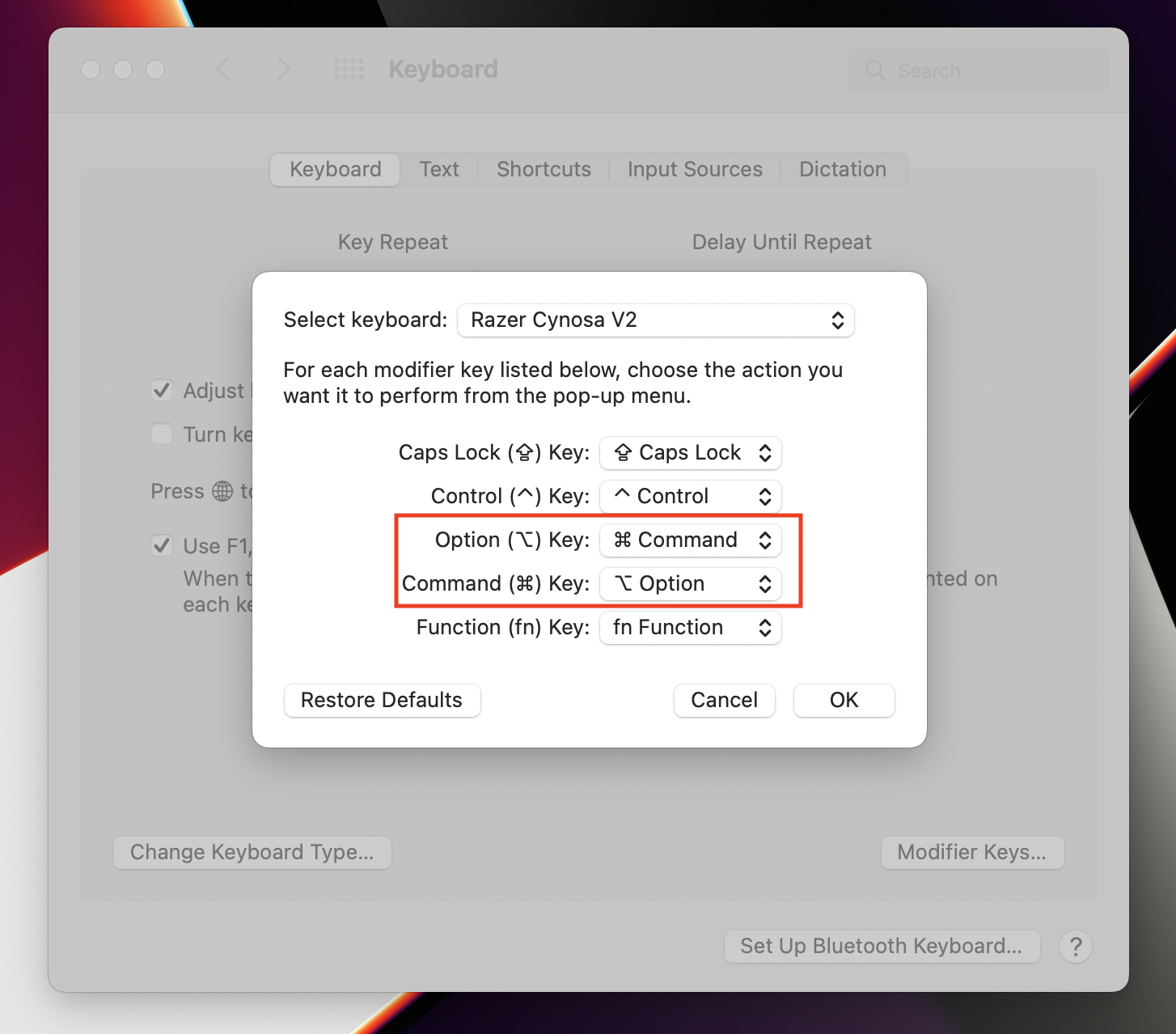
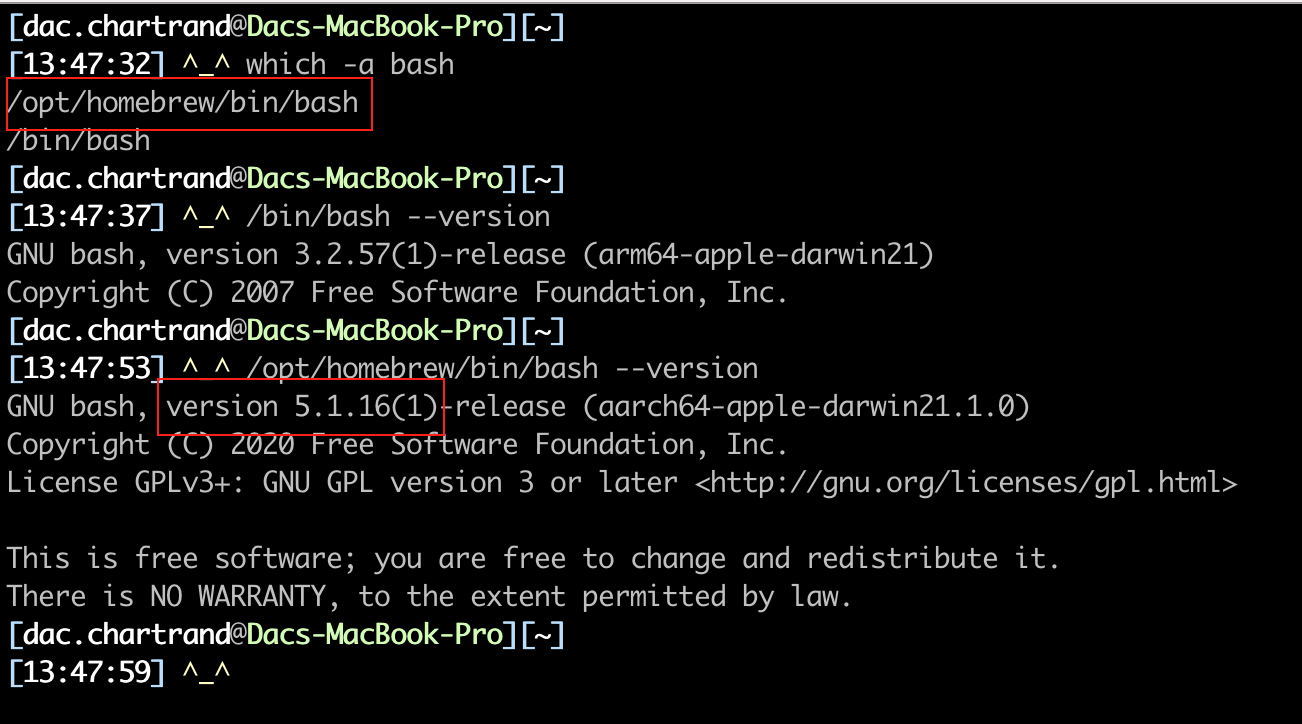
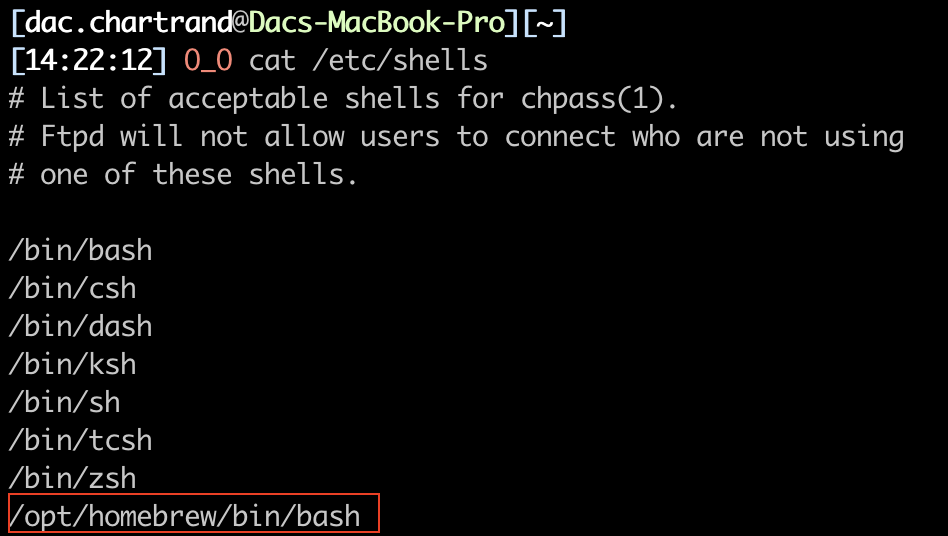
When you get a new Macbook Pro with M1 chip you get an old version of Bash.
Bash isn’t old. It’s still being maintained. It has millions of Linux and Windows users. Here’s how to put the newest version of Bash back inside your MacOS box.
reiterationsis an electronic-book containing 24 sonnets. Depending on the e-book reader that is used, each time reiterations is opened, or each time a page in the book is turned, a JavaScript software integrated into the book recomposes the book’s 24 sonnets. In this way, the book automatically generates a new and unique reading experience with each reading. Each time the poems are generated the previous versions are lost and cannot be retrieved. The number of unique sonnets produced by the software is inhumanly vast.