Running Ubuntu 22.04 LTS on Windows 11 is a breeze.
First, install Windows Terminal and Ubuntu from the Microsoft store. Next, in Ubuntu, setup your .bash_aliases hacks and sudo apt installs. Finally, windows_98_tada.wav
Tip 1: Make sure the line endings in your .bash_aliases file are LF and not CRLF or you’ll get weird “not found” errors. Tip 2: cd-home is my alias to cd /mnt/c/Users/ME
If you’re like me, a developer who wants Ubuntu not Windows to be the main environment when working, create a /etc/wsl.conf file with:
This makes file permissions in /mnt/c behave like how you would expect in Linux. More info.
After this change all files in /mnt/c/Program Files/ and /mnt/c/Program Files (x86)/ requires the WSL terminal to be started as administrator to be able to modify permissions (aka chmod +x) and it is not currently possible to change permissions in /mnt/c/Windows/
To make Git in Windows more compatible with your workflow (not Git in Ubuntu leave it alone) add this to your .gitconfig
This blog post is about Spiral Framework and Roadrunner Server. I’ll briefly talk about what they are, then show how to compile a custom Roadrunner server, start developing with Spiral, using Docker.
Explain Like I’m 5 PHP Developers
Roadrunner works by creating a HTTP server with Golang’s excellent net/http package, and using Goridge as a bridge to pass PSR7 Request and Responses between PHP and Go. The PHP application is then a long-running, already bootstrapped PSR7-capable application that received the already parsed PSR7 request, dispatches it, and collects the response to give back into Go. [1]
Roadrunner offloads unnecessary operations from PHP to a more optimized server, and effectively swaps out the classic setup of Nginx+FPM with a PHP/Golang application that boosts flexibility and performance. [2]
Roadrunner can serve static files without the presence of Nginx, therefore, simplifying the creation of Docker containers. [3]
You can extend your PHP application by including Go libraries, [4], writing Go HTTP middleware, [5], or tweaking and extending the Roadrunner server. [6]
Spiral is a PHP Framework with a customized Roadrunner server. The main difference is that, when you use Spiral’s version of Roadrunner, it comes with more out-of-the-box solutions for PHP developers, Ie.
cd ~/hello-spiral
mkdir server
cd server
wget https://raw.githubusercontent.com/spiral/framework/master/main.go
wget https://raw.githubusercontent.com/spiral/framework/master/go.mod
Montrealer’s who won’t let PHP go (pun intended), get in on that sweet venture capital? Here are two fantastic PHP options for doing machine learning (ML), artificial intelligence (AI), and unprecedented memorization (Singularity), in a dev stack we’re already pretty good at:
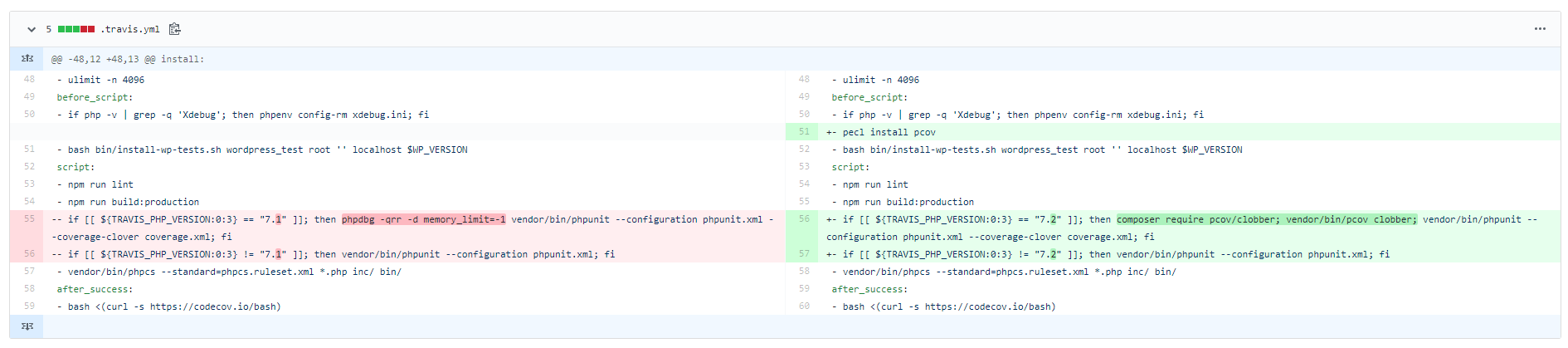
Because my project is a WordPress plugin, and because WordPress has unresolved issues older than my 9-year-old, they don’t support PHPUnit 8, yet.
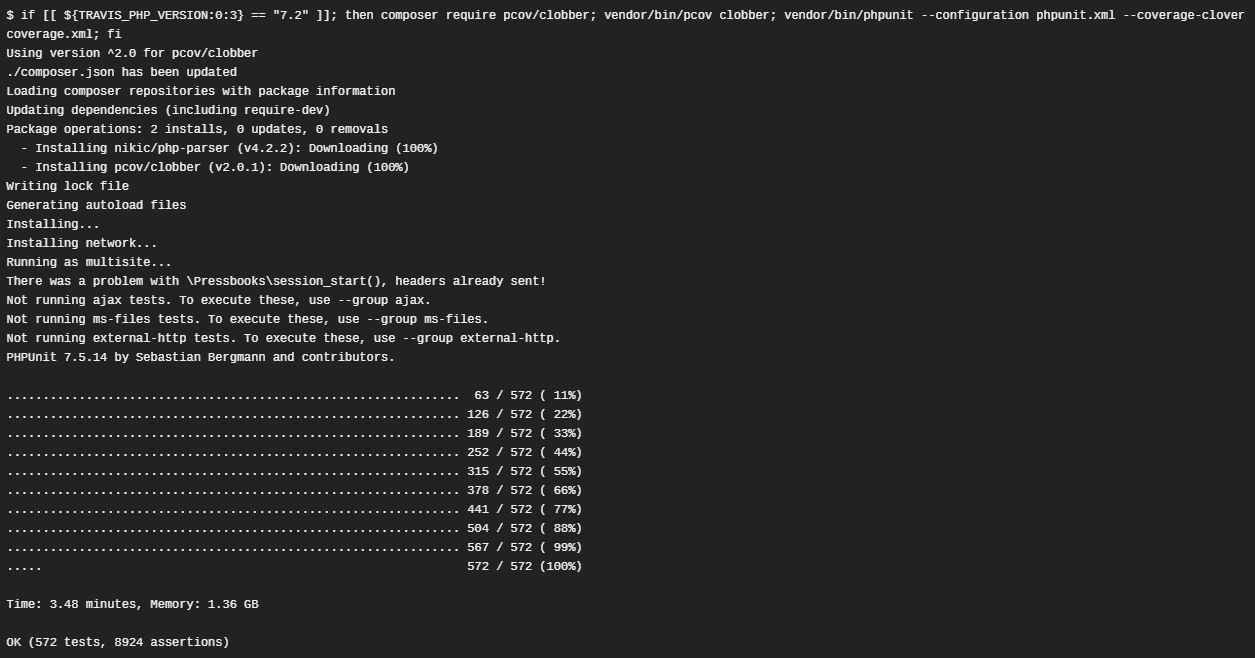
Lucky for me, unlucky for the maintainer who would rather not support this gross hack, pcov works with PHPUnit 7, and probably PHPUnit 6, thanks to pcov-clobber.
PHPUnit without Xdebug took 5 minutes. PHPUnit with Xdebug (to generate code coverage reports) took ~50 minutes. This was too long for Travis CI. The job would crash, abort, and never finish code coverage.
Fixed by switching to phpdbg. It ran 10x faster. Maybe the code coverage metrics were a bit worse but at least it ran.
All was well until it wasn’t. Last week phpdbg started crashing Travis CI with [PHP Fatal error: Out of memory].
I needed another solution. Enter pcov.
How to switch to pcov if you are stuck with PHPUnit 7
Your form will still be slow but the user experience will be better. They will see a progress bar and see status updates in real time. The idea is to refactor something like this:
/**
* A task that takes way too loooooooooooooooooooooooong...
*/
function task() {
step1();
step2();
step3();
//
step100();
}
Into this:
/**
* Yields a key/value pair
* The key is between 1-100 and represents percentage completed
* The value is a string of information for the user
*
* @return Generator
*/
function taskGenerator() {
step1();
yield 1 => 'Completed step 1';
step2();
yield 2 => 'Completed step 2';
step3();
yield 3 => 'Completed step 3';
//
step100();
yield 100 => 'Completed step 100';
}
/**
* A task that takes way too loooooooooooooooooooooooong...
*/
function task() {
foreach (taskGenerator() as $percentage => $info) {
// Do nothing, this is a compatibility wrapper
// that makes our generator work like a regular function
}
}
And this:
let evtSource = new EventSource(url);
Before
Imagine you have this form somewhere on your corporate intranet:
The user clicks submit. They wait, and wait, and wait. The task completes and they receive some feedback saying “everything seems fine”. It’s not particularly good but it does the job. Your company doesn’t have the resources, infrastructure, or competence to setup job queues and delegate these kind of tasks into the background. Everyone lives with it. The end.
$('#tpsreport').on('submit', function (e) {
e.preventDefault();
let formSubmitButton = $('#tpsreport :submit');
formSubmitButton.attr('disabled', true);
let form = $('#tpsreport');
let actionUrl = form.prop('action');
let eventSourceUrl = actionUrl + (actionUrl.includes('?') ? '&' : '?') + $.param(form.find(':input'));
let evtSource = new EventSource(eventSourceUrl);
evtSource.onopen = function () {
formSubmitButton.hide();
};
evtSource.onmessage = function (message) {
let bar = $('#sse-progressbar');
let info = $('#sse-info');
let data = JSON.parse(message.data);
switch (data.action) {
case 'updateStatusBar':
bar.progressbar({value: parseInt(data.percentage, 10)});
info.html(data.info);
break;
case 'complete':
evtSource.close();
if (data.error) {
bar.progressbar({value: false});
info.html(data.error);
} else {
window.location = actionUrl;
}
break;
}
};
evtSource.onerror = function () {
evtSource.close();
$('#sse-progressbar').progressbar({value: false});
$('#sse-info').html('EventStream Connection Error');
};
});
The JavaScript (and jQuery) snippet:
Targets the form with id tpsreport
Stops the form from submitting and instead
Appends all the form data as $_GET parameters to the form’s action URL then
Passes that to a new EventSource
Updates sse-progressbar and sse-info when it receives an event stream message
Redirects the user back to the action URL when complete
On the back end, the time consuming function was refactored into a generator that yields a key/value pair. The key is between 1-100 and represents percentage completed. The value is a string of information meant for the user. Once you have a generator that follows this convention, pass it to the EventEmitter. The browser will start receiving an event stream.
/**
* @return Generator
*/
function loooooooooooooooooooooooongGenerator() {
yield 10 => "Hey Peter what's happening. I'm going to need those TPS reports... ASAP...";
sleep(2);
yield 30 => "Ah, ah, I almost forgot... I'm also going to need you to go ahead and come in on Sunday, too. We, uhhh, lost some people this week and we sorta need to play catch-up. Mmmmmkay? Thaaaaaanks.";
sleep(2);
yield 50 => '...So, if you could do that, that would be great...';
sleep(2);
yield 60 => 'Excuse me, I believe you have my stapler.';
sleep(2);
yield 90 => 'PC LOAD LETTER';
sleep(2);
yield 100 => 'Success!';
}
$emitter = new \KIZU514\EventEmitter();
$emitter->emit( loooooooooooooooooooooooongGenerator() );
Key ideas:
It’s not necessary to wait until the request finishes, PHP can emit event-stream responses (SSE) back to the web browser while it is working on something.
PHP Generators are a relatively simple refactoring hack to get those responses back to the browser.
sleep() is only meant as an example of a function call that takes a long time to finish, don’t put sleep in your production code, you already knew this, I hope?
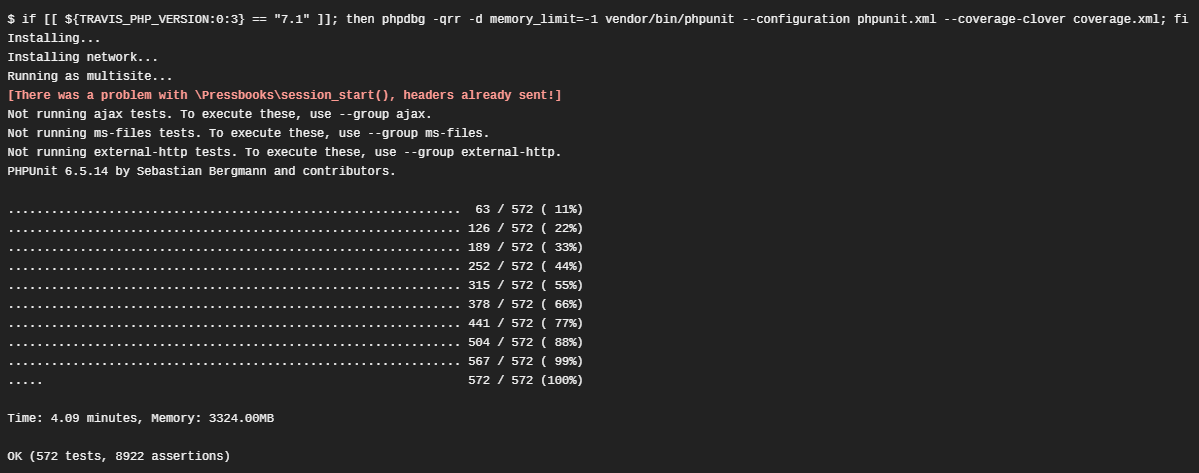
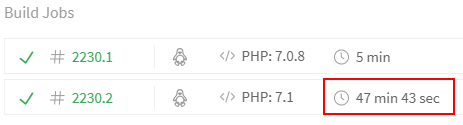
I work on a project that uses Travis CI to test and build against three jobs. (PHP 7.0, 7.1, 7.2) I recently ran into a roadblock where Travis would fail with “No output has been received” on the job that did code coverage using Xdebug. A screenshot of the last successful build before the failure:
PHP 7.0.8 runs the tests without Xdebug and PHP 7.1 runs the same tests with Xdebug + Code coverage.
Only one of our three jobs runs code coverage because it’s ridiculously slow. We were disabling coverage on the other jobs so that, in a worse case scenario, we could at least check a hotfix in under 5 minutes.
This system was working fine until a few days ago. The test suite has kept growing and we got to the point where Travis just wouldn’t run code coverage anymore.
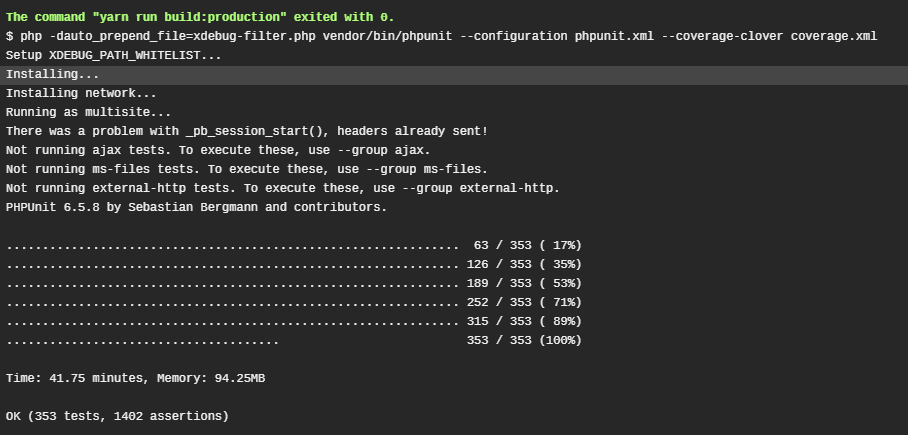
We tried every trickin thebook and the best I could get it down to, minus the other stuff required to build (git clone, install dependencies, yarn build, phpcs, …) was 42 minutes.
Hooray the build didn’t crash and it only took 42 minutes to check!
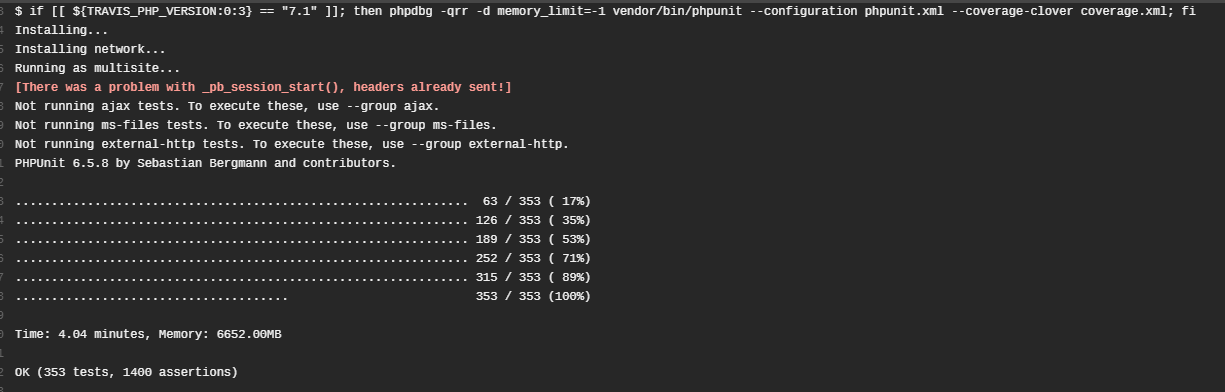
Enter Phpdbg
PHP 7.0.8 runs the tests without Phpdbg and PHP 7.1 runs the same tests with Phpdbg + Code coverage.WAT?!
Travis CI docs say to do phpenv config-rm xdebug.ini but this crashes the build on environments where Xdebug is not installed. Fixed by conditionally checking if Xdebug is on:
before_script:
- if php -v | grep -q 'Xdebug'; then phpenv config-rm xdebug.ini; fi
phpdbg didn’t work in PHP 7.2: /home/travis/.travis/job_stages: line 57: 8492 Segmentation fault (core dumped). Fixed by running phpdbg only on PHP 7.1:
script:
- if [[ ${TRAVIS_PHP_VERSION:0:3} == "7.1" ]]; then phpdbg -qrr -d memory_limit=-1 vendor/bin/phpunit --configuration phpunit.xml --coverage-clover coverage.xml; fi
- if [[ ${TRAVIS_PHP_VERSION:0:3} != "7.1" ]]; then vendor/bin/phpunit --configuration phpunit.xml; fi
A test that uses exec didn’t work: Unable to fork […] Fixed by only running that test when phpdbg is disabled. As we have three jobs (PHP 7.0, 7.1, and 7.2) and two of them don’t run code coverage (PHP 7.0 and 7.2) the test itself still runs, we just lose a bit of code coverage when running against PHP 7.1:
$runtime = new \SebastianBergmann\Environment\Runtime();
if ( ! $runtime->isPHPDBG() ) {
// // TODO: exec(): Unable to fork error when running phpdbg()
}
“The output is not the same…” Fixed by not giving a shit? Is there really 42 minutes of justifiable output difference between Xdebug and Phpdbg? Our codecov metrics remained the same. Our Travis build stopped failing.
PHP made a lot of mistakes. Many are still in the language today. However PHP is 23 years old now. PHP7, released December 2015 is a huge improvement over older versions. PHP7 outperforms Ruby, Python, and many others. If you haven’t looked at it this year, do so. “PHP sucks” is mostly FUD now.
The WordPress REST API has been available since 4.7. It’s robust, consistent, and nifty to work with. Why? Backend and mobile developers can use other frameworks while still keeping WordPress around for their customers. Frontend developers can build sites using JavaScript without having to touch PHP. Up is down, left is right, dogs and cats living together… Let’s get started!